


一般而言,网站都是欢迎搜索引擎蜘蛛来访的,毕竟只有被搜索引擎爬才有可能增加网站的收录量,但是真实的情况是,越来越多的搜索引擎、垃圾爬虫层出不穷,且不说有没有价值,有些不成熟的搜索引擎甚至能把网站给爬崩了,比如某日头条,菊花花瓣等,更有很多不知名的搜索引擎。
对于网站运营者来说,这些垃圾爬虫对网站会造成一定的压力,且意义不是很大。因此上我们需要将这些蜘蛛拒之门外,禁止他们的访问。
一般来说,搜索引擎蜘蛛的User-Agent标识都会带有:compatible; bingbot/2.0等标识,且尾部会带有一个可访问的URL。
一、常见的蜘蛛机器UA标识:
1、百度蜘蛛UA标识:
Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)百度的蜘蛛目前来说,对我们来说还是挺重要的,一般我们是欢迎百度蜘蛛的来访的,而且这只蜘蛛可不像其他蜘蛛那样跑的勤快,一般来说我们无需对百度做任何操作。
2、Google蜘蛛的UA标识:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.5304.110 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)可以说重要也不重要,因为众所周知的一些原因,我们几乎不能正常使用Google,但是这个蜘蛛爬的挺勤快的,所以这个蜘蛛大家自行权衡。
3、华为花瓣的UA标识:
Mozilla/5.0 (Linux; Android 7.0;) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; PetalBot;+https://webmaster.petalsearch.com/site/petalbot)华为自己搞的搜索引擎,和今日头条一样,饥饿的时候疯狂爬数据,会对服务器造成不小压力,而且这个搜索引擎现在国内也访问不了,没多大用途,建议屏蔽。
4、DotBot蜘蛛爬虫UA标识:
Mozilla/5.0 (compatible; DotBot/1.2; +https://opensiteexplorer.org/dotbot; help@moz.com)DotBot是国外Moz旗下链接分析网站opensiteexplorer的,DotBot蜘蛛专门用来分析网站的外链数据。以前听说MOZ蜘蛛有点重要,但实际上没多大用途,不过好在这个蜘蛛不那么贪婪,可以暂且留着。
5、AhrefsBot蜘蛛UA标识:
Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)AhrefsBot是一个国外的搜索引擎蜘蛛。不过对你的网站来说除了浪费资源外,没有任何好处。AhrefsBot是一个营销网站的爬取蜘蛛,负责分析你网站的链接信息,这个工具对于国内用户来说基本上无用。
6、一个不知道是什么蜘蛛的UA:
Mozilla/5.0 (compatible; Barkrowler/0.9; +https://babbar.tech/crawler)二、如何屏蔽这些爬虫,不让其爬取呢
常见的屏蔽蜘蛛的方法主要有三种,依据操作难易程度,分别如下:
2.1 使用robots.txt文件屏蔽蜘蛛
大部分的搜索引擎都遵守robot协议,所以可以通过robots.txt文件来告知蜘蛛,不要再来了。
如:屏蔽华为花瓣PetalBot 蜘蛛:
User-agent: PetalBot
Disallow: /屏蔽谷歌Googlebot蜘蛛:
User-agent: Googlebot
Disallow: /屏蔽AhrefsBot蜘蛛:
User-agent: AhrefsBot
Disallow: /规则是:取蜘蛛UA标识中,“compatible;” 之后,“/”之前的字符串,如:DotBot,屏蔽多个蜘蛛,只需要连续写多个即可,如:
User-agent: *
Disallow:
User-agent: Googlebot
Disallow: /
User-agent: PetalBot
Disallow: /
User-agent: AhrefsBot
Disallow: /
User-agent: Barkrowler
Disallow: /不过,这个方法的效用是很有限的,首先,如华为文档中说的,即便你设置了,也可能几个月之后他们才会发现并更新数据库。其次,还是有很多垃圾蜘蛛存在的,这些蜘蛛可不那么讲武德,所以,robots.txt的方法,适当列一些就好了。说实话,这东西,全靠自觉。
2.2 封禁蜘蛛公布的IP段资源
大部分的搜索引擎都会公布自己爬虫的网址,一般都可以通过UA标识后面的网址进行查询,我们可以将这些IP段添加到我们服务器的IP黑名单中。
不过现在的蜘蛛都不太规矩了,有些很含蓄的告诉你,你需要自己去反查,有些甚至不直接公布。所以封禁IP的方式,也不太全面。
2.3 服务器Nginx屏蔽禁止
Nginx屏蔽爬虫方法: 通过修改Nginx的配置文件nginx.conf,禁止网络爬虫的user_agent,返回403。具体操作方法是:
1、进入nginx的配置目录,例如cd /usr/local/nginx/conf
2、添加agent_deny.conf配置文件 vim agent_deny.conf
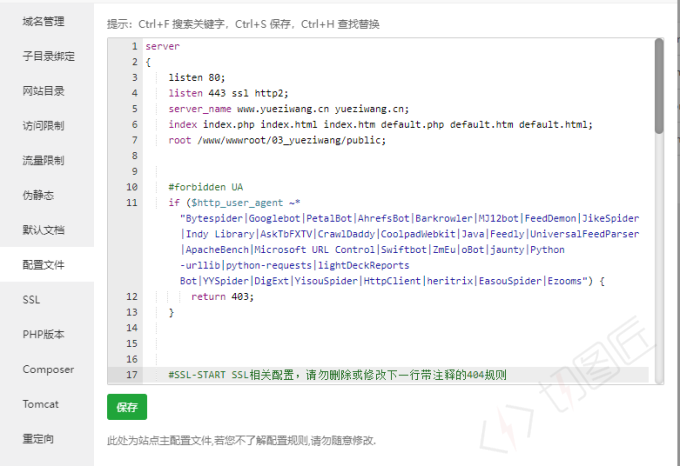
如果您使用的是宝塔面板的话,需要进入到站点设置里,点击【配置文件】,在配置文件的Server里面进行添加如下代码:
#forbidden UA
if ($http_user_agent ~* "Bytespider|Googlebot|PetalBot|AhrefsBot|Barkrowler") {
return 403;
}
常见的错误操作是,直接进入到软件商店,在运行环境下,找到Nginx,点击配置进入Nginx管理,点击配置修改,找到server层:
#forbidden UA
if ($http_user_agent ~* "Bytespider|Googlebot|PetalBot|AhrefsBot|Barkrowler|MJ12bot|FeedDemon|JikeSpider|Indy Library|AskTbFXTV|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|python-requests|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|heritrix|EasouSpider|Ezooms") {
return 403;
}当时我也是在这里掉了坑,折腾了好半天没效果,后来发现是设置错了地方,希望对大家有用。另外,其实垃圾爬虫不仅仅这几个,我们整理了常见的一些垃圾爬虫及对应的配置代码,供大家参考:
#forbidden UA
if ($http_user_agent ~* "Bytespider|Googlebot|PetalBot|AhrefsBot|Barkrowler|MJ12bot|FeedDemon|JikeSpider|Indy Library|AskTbFXTV|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|python-requests|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|heritrix|EasouSpider|Ezooms") {
return 403;
}三、一些常见的爬虫及简要说明
另外,我们整理了一些常见的爬虫,及其简要说明,供大家参考
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!)
jikeSpider 无用爬虫
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress 爆破扫描器
oBot 无用爬虫
Python-urllib 内容采集
Python-requests 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫













评论前必须登录!
注册